Оператор языка SQL SELECT предназначен для запросов на выборку данных из базы данных. Он может быть использован как без условий (выбор всех строк во всех столбцах или всех строк в определённых столбцах), так и с многочисленными условиями (выбор определённых строк), которые заданы в секции WHERE. Ознакомимся со средствами SQL, которыми можно задавать эти условия на выборку данных, а также узнаем, как использовать оператор SELECT в подзапросах.
SELECT для выбора столбцов таблицы
Запрос с оператором SELECT для выбора всех столбцов таблицы имеет следующий синтаксис:
SELECT * FROM ИМЯ_ТАБЛИЦЫ
То есть для выбора всех столбцов таблицы после слова SELECT нужно ставить звёздочку.
Пример 1. Есть база данных фирмы - Company. В ней есть таблица Org (Структура фирмы) и Staff (Сотрудники). Требуется выбрать из таблиц все столбцы. Соответствующий запрос для выбора всех столбцов из таблицы Org выглядит следующим образом:
SELECT * FROM ORG
Этот запрос вернёт следующее (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
Запрос для выбора всех столбцов из таблицы Staff выглядит следующим образом:
SELECT * FROM STAFF
Этот запрос вернёт следующее:

Для выбора определённых столбцов таблицы нам потребуется вместо звёздочки перечислить через запятую названия всех столбцов, которые требуется выбрать:
SELECT ВЫБИРАЕМЫЕ_СТОЛБЦЫ FROM ИМЯ_ТАБЛИЦЫ
Пример 2. Пусть требуется из таблицы Org выбрать столбцы Depnumb и Deptname, в которых содержатся данные соответственно о номерах отделов фирмы и об их названиях. Запрос для получения такой выборки будет следующим:
SELECT DEPNUMB, DEPTNAME FROM ORG
А из таблицы Staff нужно выбрать столбцы DEPT, NAME, JOB, в которых содержатся соответственно данные о номере отдела, в котором трудится сотрудник, его имени и должности:
SELECT DEPT, NAME, JOB FROM STAFF
Для выбора определённых строк таблицы вместе с оператором SELECT уже потребуется ключевое слово WHERE, указывающее на некоторое значение или несколько значений, содержащиеся в интересующих нас строках. Наиболее простые условия задаются при помощи операторов сравнения и равенства (, =), а также ключевого слова IS. Условий может быть несколько, тогда они перечисляются с использованием ключевого слова AND. Запросы для выбора строк имеют следующий синтаксис:
Пример 4. В предыдущем примере мы выбирали строки из таблицы только по значению одного столбца - DEPT. Пусть теперь нужно выбрать данные о сотрудниках, которые работают в 38-м отделе и должность которых - служащий (Clerk). Для этого в секции WHERE соответствующие значения нужно перечислить с использованием слова AND:

Пример 5. Пусть нужно выбрать из таблицы Staff идентификаторы и имена тех сотрудников, размер комиссии которых - неопределённый. Для этого в секции WHERE перед указанием значения столбца COMM - NULL нужно ставить не знак равенства, а слово IS:
Этот запрос вернёт следующие данные:

Для указания значений в строках, которые требуется выбрать, используются и знаки сравнения.
Использование SELECT и предикатов IN, OR, BETWEEN, LIKE
Предикаты - слова IN, OR, BETWEEN, LIKE в секции WHERE - также позволяют выбрать определённые диапазоны значений (IN, OR, BETWEEN) или значения в строках (LIKE), которые требуется выбрать из таблицы. Запросы с предикатами IN, OR, BETWEEN имеют следующий синтаксис:
Запросы с предикатом LIKE имеют следующий синтаксис:
Пример 7. Пусть требуется выбрать из таблицы Staff имена, должности и число отработанных лет сотрудников, работающих в отделах с номерами 20 или 84. Это можно сделать следующим запросом:
Результат выполнения запроса:

Пример 8. Пусть теперь требуется выбрать из таблицы Staff те же данные, что и в предыдущем примере. Запрос со словом OR аналогичен запросу со словом IN и перечислением интересующих значений в скобках. Запрос будет следующим:
Пример 9. Выберем из той же таблицы имена, должности и число отработанных лет сотрудников, зарплата которых между 15000 и 17000 включительно:
Результат выполнения запроса:

Предикат LIKE используется для выборки тех строк, в значениях которых встречаются символы, указанные после предиката между апострофами (").
Пример 10. Выберем из той же таблицы имена, должности и число отработанных лет сотрудников, имена которых начинаются с буквы S и состоят из 7 символов:
Символ подчёркивания (_) означает любой символ. Результат выполнения запроса:

Пример 11. Выберем из той же таблицы имена, должности и число отработанных лет сотрудников, имена которых начинаются с буквы S и содержат любые другие буквы в любом количестве:
Символ процентов (%) означает любое количество символов. Результат выполнения запроса:

Значения, указанные с использованием предикатов IN, OR, BETWEEN, LIKE можно инвертировать при помощи слова NOT. Тогда запрашиваемые данные будут иметь противоположный смысл. Если мы используем NOT IN (20, 84), то будут выведены данные сотрудников, которые работают во всех отделах, кроме имеющих номера 20 и 84. С использованием NOT BETWEEN 15000 AND 17000 можно получить данные сотрудников, зарплата которых не входит в интервал от 15000 до 17000. Запрос с NOT LIKE выведет данные сотрудников, чьи имена не начинаются или не содержат символов, указанных с NOT LIKE.
Написать SQL запросы с SELECT и предикатами IN, NOT IN, BETWEEN самостоятельно, а затем посмотреть решения
Есть база данных "Театр". Таблица Play содержит данные о постановках. Таблица Team - о ролях актёров. Таблица Actor - об актёрах. Таблица Director - о режиссёрах. Поля таблиц, первичные и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).

Пример 12. Вывести список актёров, которые не разу не были утверждены на главную роль. В таблице team данные о главных ролях содержатся в столбце mainteam. Если роль - главная, то в соответствующей строке отмечено "Y".
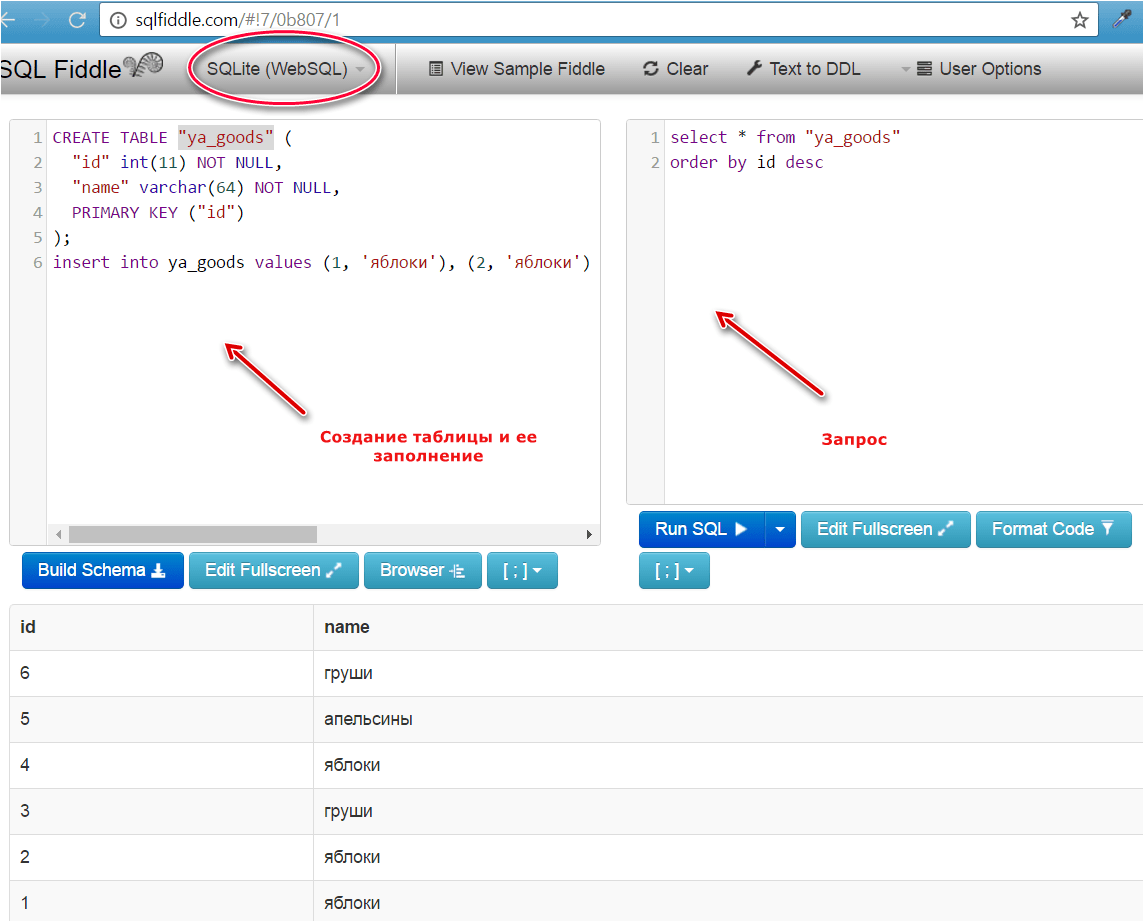
SELECT и ORDER BY - сортировка (упорядочение) строк
Разобранные до сих пор запросы SQL SELECT возвращали строки, которые могли быть расположены в любой последовательности. Однако часто требуется отсортировать строки по порядку номеров, алфавиту и другим признакам. Для этого служит ключевое словосочетание ORDER BY. Такие запросы имеют следующий синтаксис:
Пример 15. Пусть требуетя выбрать из таблицы Staff сотрудников, работающих в отделе с номером 84 и отсортировать (упорядочить) записи по числу отработанных лет в возрастающем порядке:
Слово ASC указывает, что порядок сортировки - возрастающий. Это слово не обязательно, так как возрастающий порядок сортировки применяется по умолчанию. Результат выполнения запроса:

Пример 16. Пусть требуетя выбрать те же данные, что и в предыдущем примере, но отсортировать (упорядочить) записи по числу отработанных лет в убывающем порядке:
Слово DESC указывает, что порядок сортировки - убывающий. Результат выполнения запроса:

SELECT и DISTINCT - удаление дубликатов строк
Когда для значений строк таблицы не задано условие уникальности, в результатах запроса могут встретиться одинаковые строки. Часто требуется вывести лишь уникальные строки. Это делается при помощи выражения DISTINCT после оператора SELECT.
Пример 17. Пусть требуетcя узнать, какие существуют отделы и какие должности среди отделов, номера которых меньше 30. Это можно сделать при помощи следующего запроса:
Результат выполнения запроса:

Оператор SELECT в подзапросах SQL
До сих пор мы разбирали конструкции SQL с оператором SELECT, в которых условия, по котором выбираются данные, и сами выбираемые данные содержатся в одной и той же таблице базы данных. На практике часто бывает, что данные, которые надо выбрать, содержатся в одной таблице, а условия - в другой. Здесь на помощь приходят подзапросы: значения условия отбора возвращаются из другого запроса (вложенного запроса), начинающегося также с SELECT. Запросы с подзапросами могут выдавать как одну, так и несколько строк.
Пример 18. Все те же таблицы ORG и STAFF. Пусть требуетcя узнать, в каком подразделении работает сотрудник с идентификационным номером 280, и где это подразделение расположено. Но информация о подразделениях хранится в таблице ORG, а информация о сотрудниках - в таблице STAFF. Это можно сделать при помощи следующего запроса с подзапросом, в котором внешний SELECT обращается к таблице ORG, а внутренний SELECT - к таблице STAFF:
Результат выполнения запроса:

Пример 19. Пусть теперь требуетcя узнать, в каких подразделениях (без дублирования) работают сотрудники с заработной платой менее 13000. Для этого в секции WHERE внешнего SELECT (запрос к таблице ORG) задаётся условие, принимающее диапазон значений (IN), а внутренний SELECT (к таблице STAFF) как раз возвращает требуемый диапазон значений:
Реляционные базы данных и язык SQL
Лабораторная работа № 2
Тема : Простые запросы на выборку данных средствами SQL .
Цель работы : Изучить синтаксис инструкции SQL SELECT , для создания простых запросов на выборку данных. Используя предложения WHERE задать условия отбора строк из таблиц определенных в предложении FROM . Изучить организацию выборки данных из нескольких таблиц БД.
1. Выборка данных.
Для извлечения записей из таблиц в SQL определен оператор SELECT . С помощью этой команды осуществляется не только операция реляционной алгебры "выборка" (селекция), но и предварительное соединение (join) двух и более таблиц. Это наиболее сложное и мощное средство SQL, полный синтаксис оператора SELECT имеет вид:
SELECT < список _ выбора >
FROM <имя_таблицы>, ...
[ WHERE <условие> ]
[ GROUP BY <имя_столбца>,... ]
[ HAVING < условие > ]
,... ]
Все примеры, приведенные ниже, касающиеся базы данных publications используют пример лабораторной работы № 1 (lab _1_ CREATE _ TABLE . htm ) поэтому результаты запросов на создание таблиц здесь не приводятся.
Порядок предложений в операторе SELECT должен строго соблюдаться (например, GROUP BY должно всегда предшествовать ORDER BY ), иначе это приведет к появлению ошибок.
Этот оператор всегда начинается с ключевого слова SELECT . В конструкции <список_выбора> определяется столбец или столбцы, включаемые в результат. Он может состоять из имен одного или нескольких столбцов, или из одного символа «*» (звездочка), определяющего все столбцы. Элементы списка разделяются запятыми.
SELECT author FROM authors ;
получить список всех полей таблицы authors :
SELECT * FROM authors ;
В том случае, когда нас интересуют не все записи, а только те, которые удовлетворяют некому условию, это условие можно указать после ключевого слова WHERE . Например, найдем все книги, опубликованные после 1996 года:
SELECT title FROM titles WHERE yearpub > 1996;
Допустим теперь, что надо найти все публикации за интервал 1995 - 1997 гг. Это условие можно записать в виде :
SELECT title FROM titles WHERE yearpub>=1995 AND yearpub<=1997;
В заключение заметим, что при выполнении оператора SELECT результирующее отношение может иметь несколько записей с одинаковыми значениями всех полей. Чтобы исключить повторяющиеся записи из выборки используется ключевое слово DISTINCT . Ключевое слово ALL указывает, что в результат необходимо включать все строки.
2. Выборка из нескольких таблиц.
Очень часто возникает ситуация, когда выборку данных надо производить из отношения, которое является результатом слияния двух других отношений. Например, нужно получить из базы данных publications информацию обо всех печатных изданиях в виде следующей таблицы:
|
title |
yearpub |
publisher |
Для этого СУБД предварительно должна выполнить слияние таблиц titles и publishers , и только затем произвести выборку из полученного отношения.
Для выполнения операции такого рода в операторе SELECT после ключевого слова FROM указывается список таблиц, по которым производится поиск данных. После ключевого слова WHERE указывается условие, по которому производится слияние. Для того, чтобы выполнить данный запрос, нужно дать команду:
SELECT titles . title , titles . yearpub , publishers . publisher
FROM titles,publishers
WHERE titles.pub_id=publishers.pub_id;
Пример, где одновременно задаются условия и слияния, и выборки (результат предыдущего запроса ограничивается изданиями после 1996 года):
SELECT titles.title,titles.yearpub,publishers.publisher
FROM titles,publishers
WHERE titles.pub_id=publishers.pub_id AND
titles.yearpub>1996;
Следует обратить внимание на то, что когда в разных таблицах присутствуют одноименные поля, то для устранения неоднозначности перед именем поля указывается имя таблицы и знак "." (точка). (Рекомендуется имя таблицы указывать всегда! )
Естественно, имеется возможность производить слияние и более чем двух таблиц. Например, чтобы дополнить описанную выше выборку именами авторов книг необходимо составить оператор следующего вида:
Publishers.publisher
FROM titles,publishers,titleauthors,authors
WHERE titleauthors.au_id=authors.au_id AND
Titleauthors.title_id=titles.title_id AND
Titles.pub_id=publishers.pub_id AND
Titles . yearpub > 1996;
Альтернативный вариант слияния нескольких таблиц может использовать оператор
соединения таблиц непосредственно в предложении FROM . Существует три
варианта оператора:
INNER JOIN соединение, при котором записи включаются в результирующий
набор только в том случае, если в связных атрибутах будут найдены одинаковые
значения;
LEFT JOIN левое соединение, при котором все записи из первой (левой)
таблицы включаются в результирующий набор, даже если во второй (правой)
таблице нет соответствующих им записей;
RIGHT JOIN правое соединение, при котором все записи из второй (правой)
таблицы включаются в результирующий набор, даже если в первой (левой) таблице
нет соответствующих им записей.
Например, предыдущий пример можно реализовать с использованием оператора
INNER JOIN следующим образом :
SELECT authors.author,titles.title,titles.yearpub,
Publishers.publisher
FROM ((titles INNER JOIN publishers ON
Titles.pub_id=publishers.pub_id)
INNER JOIN titleauthors ON
Itleauthors.title_id=titles.title_id)
INNER JOIN authors ON
Titleauthors.au_id=authors.au_id
WHERE titles.yearpub > 1996;
3. Вычисления внутри SELECT.
SQL позволяет выполнять различные арифметические операции над столбцами результирующего отношения. В конструкции <список_выбора> можно использовать константы, функции и их комбинации с арифметическими операциями и скобками. Например, чтобы узнать, сколько лет прошло с 1992 года (год принятия стандарта SQL-92) до публикации той или иной книги можно выполнить команду:
SELECT title, yearpub-1992 FROM titles WHERE yearpub > 1992;
В арифметических выражениях допускаются операции сложения (+), вычитания (-),
деления (/), умножения (*), а также различные функции (COS, SIN, ABS
абсолютное значение и т.д.).
В SQL также определены так называемые агрегатные функции, которые совершают действия над совокупностью одинаковых полей в группе записей. Среди них:
AVG(<имя поля>) - среднее по всем значениям данного поля
COUNT(<имя поля>) или COUNT (*) - число записей
MAX(<имя поля>) - максимальное из всех значений данного поля
MIN(<имя поля>) - минимальное из всех значений данного поля
SUM(<имя поля>) - сумма всех значений данного поля
Следует учитывать, что каждая агрегирующая функция возвращает единственное значение.
Примеры: определить дату публикации самой "древней" книги в нашей базе данных
SELECT MIN(yearpub) FROM titles;
SELECT COUNT (*) FROM titles ;
Область действия данных функции можно ограничить с помощью логического условия. Например, количество книг, выпущенных после 2000 года:
SELECT COUNT (*) FROM titles WHERE yearpub > 2000;
4. Функции для работы с датой
В MS Access предусмотрен целый набор встроенных функций дат и времени Перечислим некоторые из них:
Date () - текущая дата, т е сегодняшнее число, месяц и год;
D ау(дата) - извлекает из даты день, например дата - 12,09,97, число 12;
Мо nth (дата) - извлекает из даты месяц, например дата - 12,09,97, результат применения функции - число 9;
Уеаг(дата) - извлекает из даты год, например дата - 12-09,97, результат применения функции - число 97;
Weekday (дата) - извлекает из даты день недели в американской системе нумерации дней, а именно в примере - дата 12,09,97, результат применения функции - число 6, что соответствует пятнице,
DatePart (HHTepBan , дата) - здесь аргумент "интервал" - это сокращенное название нужного компонента даты, а дата - конкретное значение даты или имя поля с датой
Например:
DatePart (" H ",#12,09,97#) - день недели - 6, т е пятница,
DatePart (" HH ",#12,09,97#) - неделя года - 37,
DatePart (" K ",# 12,09,97#) - квартал года - 3
DatePart("a",#12,09,97#) - день -12,
DatePart("M",#12,09,97#) - месяц - 9, \ DatePart("rrrr",#12,09,97#) - год -1997
Пример запроса. Определить, сколько лет прошло с момента выхода статьи описавшей стандарт SQL (предположим, что название статьи ”Стандарт SQL ”)
SELECT Month(Date()-yearpub)
FROM titles INNER JOIN publishers ON
titles.pub_id = publishers.pub_id
WHERE publisher = "Стандарт SQL ";
5. Задание к лабораторной работе
Замечания по ходу выполнения лабораторной работы.
Для просмотра результата выполнения запросов необходимо чтобы в таблицах были внесены данные соответствующими сформулированным запросам. При этом данные в запросах (даты, фамилии, количество и т.п.) могут быть изменены по факту внесенных данных в БД.
При выполнении заданий лабораторной работы все вычисляемые поля заменять синонимами, используя опцию AS в предложении SELECT .
Например : SELECT COUNT (*) AS Количество _ строк FROM titles ;
Реализовать следующие запросы средствами SQL :
Найти заказы сделанные в январе.
Найти изделия, которые поставляются в количестве не меньше 10 , и не больше 100 .
Получить список изделий получаемых заказчиком “з-д «Красный луч»”, цена которых более 50 тыс. грн.
Сколько деталей «Болт» по всем заказам получил заказчик “з-д «Красный луч»”.
Определить наименования деталей заказанных в период с 6/10/ 97 по 10/10/97, которые не заказывал з-д «Красный луч».
Получить список наименований изделий, поставки которых превышают 10 тыс.
На какую сумму заказано деталей з-дом «Красный луч»
Какие заказчики заказывали деталь «Болт».
Определить среднее количество поставок детали «Болт» за 1997 год.
Найти заказчика, заказавшего самую дорогую деталь.
6. Контрольные вопросы
Какие предложения SELECT являются обязательными?
Что задает предложение WHERE?
Какие типы соединений ( JOIN ) поддерживает инструкция SELECT ?
Какая последовательность предложений инструкции SELECT ?
В каком случае обязательно указывать имя таблицы перед именем поля?
Как формировать вычисляемые поля в SELECT ?
Можно ли соединять более двух таблиц операцией JOIN ?
Какой альтернативный синтаксис операции JOIN (с использованием WHERE ) можно использовать для корректного выполнения запроса?
Раздел 4 Информационные системы
Введение в SQL.
Создание, изменение и удаление таблиц.
Выборка данных из таблицы.
Создание SQL-запросов.
Обработка данных в SQL.
Методика обучения данной теме в школе.
Введение в SQL. SQL - структурированный язык запросов, который дает возможность создавать и работать в реляционных базах данных, которые являются наборами связанной информации сохраняемой в таблицах. Язык ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц-отношений. Важнейшая особенность структур этого языка состоит в ориентации на конечный рез-тат обработки данных, а не на процедуру этой обработки. SQL сам определяет, где находятся данные, индексы и даже какие наиболее эффективные последовательности операций следует использовать для получения рез-та.
Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций: создание в базе данных новой таблицы; добавление в таблицу новых записей; изменение записей; удаление записей; выборка записей из одной или нескольких таблиц (в соответствии с заданным условием); изменение структур таблиц.
Со временем SQL обеспечил возможность описания и управления новыми хранимыми объектами (например, индексы, представления, триггеры и хранимые процедуры). SQL остаётся единственным механизмом связи между прикладным программным обеспечением и базой данных. В то же время, современные СУБД, а, также, информационные системы, использующие СУБД, предоставляют пользователю развитые средства визуального построения запросов. Каждое предложение SQL - это либо запрос данных из базы, либо обращение к базе данных, которое приводит к изменению данных в базе.
В соответствии с тем, какие изменения происходят в базе данных, различают следующие типы запросов: на создание или изменение в базе данных новых или существующих объектов; на получение данных; на добавление новых данных (записей); на удаление данных; обращения к СУБД.
Основным объектом хранения реляционной базы данных является таблица, поэтому все SQL-запросы - это операции над таблицами. В соответствии с этим, запросы делятся на:
Запросы, оперирующие самими таблицами (создание и изменение таблиц);
Запросы, оперирующие с отдельными записями (или строками таблиц) или наборами записей.
Каждая таблица описывается в виде перечисления своих полей (столбцов таблицы) с указанием: типа хранимых в каждом поле значений; связей между таблицами (задание первичных и вторичных ключей); информации, необходимой для построения индексов.
Таким образом, использование SQL сводится, по сути, к формированию всевозможных выборок строк и совершению операций над всеми записями, входящими в набор.
Команды SQL разделяются на следующие группы:
1. Команды языка определения данных - DDL (Data Definition Language). Эти SQL команды можно использовать для создания, изменения и удаления различных объектов базы данных.
2. Команды языка управления данными - DCL (Data Control Language). С помощью этих SQL команд можно управлять доступом пользователей к базе данных и использовать конкретные данные (таблицы, представления и т.д.).
3. Команды языка управления транзакциями - TCL (Тгаnsасtiоn Соntrol Language). Эти SQL команды позволяют определить исход транзакции.
4. Команды языка манипулирования данными - DML (Data Manipulation Language). Эти SQL команды позволяют пользователю перемещать данные в базу данных и из нее.
Операторы SQL делятся на:
Операторы определения данных (Data Definition Language, DDL )
CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.)
ALTER изменяет объект
DROP удаляет объект
Операторы манипуляции данными (Data Manipulation Language, DML )
SELECT считывает данные, удовлетворяющие заданным условиям
INSERT добавляет новые данные
UPDATE изменяет существующие данные
DELETE удаляет данные
Операторы определения доступа к данным (Data Control Language, DCL )
GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
REVOKE отзывает ранее выданные разрешения
DENY задает запрет, имеющий приоритет над разрешением
Операторы управления транзакциями (Transaction Control Language, TCL )
COMMIT применяет транзакцию.
ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции.
SAVEPOINT делит транзакцию на более мелкие участки.
Преимущества: 1.Независимость от конкретной СУБД (тексты SQL-запросов, содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую). 2. Наличие стандартов (наличие стандартов и набора тестов для выявления совместимости и соответствия конкретной реализации SQL общепринятому стандарту только способствует «стабилизации» языка). 3. Декларативность (с помощью SQL программист описывает только то, какие данные нужно извлечь или модифицировать)
Недостатки: 1.Несоответствие реляционной модели данных 2.Повторяющиеся строки 3. Неопределённые значения (nulls) 4. Явное указание порядка колонок слева направо 5. Колонки без имени и дублирующиеся имена колонок 6. Отсутствие поддержки свойства «=» 7. Использование указателей 8. Высокая избыточность
2.2 Создание, изменение и удаление таблиц.
Создание таблицы:
Таблицы создаются командой CREATE TABLE. Эта команда создает пустую таблицу - таблицу без строк. Значения вводятся с помощью DML команды INSERT. Команда CREATE TABLE в основном определяет им таблицы, в виде описания набора имен столбцов указанных в определенном порядке. Она также определяет типы данных и размеры столбцов. Каждая таблица должна иметь по крайней мере один столбец.
Синтаксис команды:
CREATE TABLE
(
Изменение таблицы:
Команда ALTER TABLE – это содержательна форма, хотя ее возможности несколько ограничены. Она используется чтобы изменить определение существующей таблицы. Обычно, она добавляет столбцы к таблице. Иногда она может удалять столбцы или изменять их размеры, а также в некоторых программах добавлять или удалять ограничения. Типичный синтаксис чтобы добавить столбец к таблице:
ALTER TABLE


| /*teachers*/ CREATE TABLE `teachers` ( `id` INT (11 ) NOT NULL , `name` VARCHAR (25 ) NOT NULL , `code` INT (11 ) , `zarplata` INT (11 ) , `premia` INT (11 ) , PRIMARY KEY (`id` ) ) ; INSERT INTO teachers VALUES (1 , "Иванов" , 1 , 10000 , 500 ) , (2 , "Петров" , 1 , 15000 , 1000 ) , (3 , "Сидоров" , 1 , 14000 , 800 ) , (4 , "Боброва" , 1 , 11000 , 800 ) ; /*lessons*/ CREATE TABLE `lessons` ( `id` INT (11 ) NOT NULL , `tid` INT (11 ) , `course` VARCHAR (25 ) , `date` VARCHAR (25 ) , PRIMARY KEY (`id` ) ) ; INSERT INTO lessons VALUES (1 , 1 , "php" , "2015-05-04" ) , (2 , 1 , "xml" , "2016-13-12" ) ; /*courses*/ CREATE TABLE `courses` ( `id` INT (11 ) NOT NULL , `tid` INT (11 ) , `title` VARCHAR (25 ) , `length` INT (11 ) , PRIMARY KEY (`id` ) ) ; INSERT INTO courses VALUES (1 , 1 , "php" , 54 ) , (2 , 1 , "xml" , 72 ) , (3 , 2 , "sql" , 25 ) ; |
/*teachers*/ CREATE TABLE `teachers` (`id` int(11) NOT NULL, `name` varchar(25) NOT NULL, `code` int(11), `zarplata` int(11), `premia` int(11), PRIMARY KEY (`id`)); insert into teachers values (1, "Иванов",1,10000,500), (2, "Петров",1,15000,1000) ,(3, "Сидоров",1,14000,800), (4,"Боброва",1,11000,800); /*lessons*/ CREATE TABLE `lessons` (`id` int(11) NOT NULL, `tid` int(11), `course` varchar(25), `date` varchar(25), PRIMARY KEY (`id`)); insert into lessons values (1,1, "php","2015-05-04"), (2,1, "xml","2016-13-12"); /*courses*/ CREATE TABLE `courses` (`id` int(11) NOT NULL, `tid` int(11), `title` varchar(25), `length` int(11), PRIMARY KEY (`id`)); insert into courses values (1,1, "php",54), (2,1, "xml",72), (3,2, "sql",25);
В результате получим таблицы с данными:
Отправка запроса:
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/ :
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application .
- Меню Schema -> Import .
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных

Выборка данных из таблицы в SQL осуществляется с помощью следующей конструкции:
SELECT
*|
[AS
] FROM
[WHERE
[AND
]]
[GROUP BY | [HAVING
]]
[ORDER BY
[COLLATE
]
]
Раздел SELECT
→ Определить список выходных столбцов
Список выходных столбцов может быть указан несколькими способами:
. Указать символ *, обозначающий включение в результаты запроса всех колонок запроса в естественной последовательности.
. Перечислить в желательном порядке только нужные.
Пример: SELECT * FROM Customer
→ Включить вычисляемые столбцы
В качестве вычисляемых столбцов запроса могут выступать:
. Результаты простейших арифметических выражения (+, -, /, *_ или конкатенации строк (||).
. Результаты функций агрегирования COUNT(*)|{AVG|SUM|MAX|MIN|COUNT} (
)
Примечание
: В SQL Server дополнительно можно использовать оператор % — модуль (целый остаток от деления).
→ Включить константы
В качестве столбцов могут выступать константы числового и символьного типов.
Примечание : SELECT DISTINCT ‘Для ‘, SNum, Comm*100, ‘%’, SName FROM SalesPeople
→ Переименовать выходные столбцы
Вычисляемым, а также любым другим столбцам, при желании, можно присвоить уникальное имя с помощью ключевого слова AS: AS
Примечание : В SQL SERVER дать новое имя столбцу можно с помощью оператора присвоения =
→ Указать принцип обработки дублей строк
DISTINCT – запрещает появление строк-дублей в выходном множестве. Его можно задавать один раз для оператора SELECT. На практика первоначально формируется выходное множество, упорядочивается, а затем из него удаляются повторяющиеся значения. Обычно это занимает много времени и не следует этим злоупотреблять.
ALL (действует по умолчанию) – обеспечивает включение в результаты запроса и повторяющихся значений
→ Включить агрегатные функции
Функции агрегирования (функции над множествами, статистические или базовые) предназначены для вычисления некоторых значений для заданного множества строк. Используются следующие агрегатные функции:
. AVG|SUM(|) – подсчитывает среднее значение | сумму от или, возможно без учета дублей, игнорируя NULL.
. MIN|MAX() – находит максимальное | минимальное значение.
. COUNT(*) – подсчитывает число строк во множестве с учетом NULL значений | значений в столбце, игнорируя NULL значения, возможно без дублей.
Примечания по использованию
:
. Функции агрегирования нельзя вкладывать друг в друга.
. Из-за значений NULL выражение SUM(F1)-SUN(F2)Sum(F1-F2)
. Внутри функций агрегирования допустимы выражения AVG(Comm*100)
. Если в результате запроса не получено ни одной строки или все значения равны NULL, то функция COUNT возвращает 0, а другие – NULL.
. Функции AVG и SUM могут применяться только для числовых типов, данных в Interval, а остальные могут использоваться для любых типов данных.
. Функция COUNT возвращает целое число (типа Integer), а другие наследуют типы данных обрабатываемых значений, вследствие чего следует следить за точностью результата функции SUM (возможно переполнение) и масштабом функции AVG.
Примеры на агрегатные функции:
SELECT COUNT(*) FROM Customer
. SELECT COUNT(DISTINCT SNum) FROM Orders
. SELECT MAX(Amt+Binc) FROM Orders //Если Binc – дополнительное числовое поле в Orders
. SELECT AVG(Comm*100) FROM SalesPeople //Выражение внутри функции
→ Особенности промышленных серверов
В СУБД Oracle в разделе SELECT можно указывать дополнительные указания-подсказки (hints) (27 штук), влияющие на выбор типа оптимизатора запросов и его работу.
SELECT /*+ ALL_ROWS */ FROM Orders… //наилучшая производительность
В СУБД SQL Server
:
] – задает количество или процент считываемых строк. При одинаковых последних значениях возможно считывание всех таких строк и общее число может быть больше указанного.
DECLARE @p AS Int
SELECT @p=10
SELECT TOP(@p) WITH TIES * FROM Orders
Раздел FROM
Этот раздел является обязательным и позволяет:
→ Указать имена исходных таблиц
В разделе FROM указываются имена таблиц и/или представлений, из которых будут извлекаться данные. Причем одна и та же таблица может несколько раз входить в этот раздел.
Примечание: В СУБД Oracle можно выбирать строки и из снимков (Snapshot).
→ Указать псевдонимы таблиц
Под псевдонимом таблицы понимается дополнительный, обычно краткий идентификатор, указываемый через пробел после имени таблицы/представления.
Пример: Customer C
→ Указать вариант внешнего объединения таблиц
Если в разделе FROM указано несколько таблиц, то все они неявно считаются внешними соединениями. В стандарте предусмотрены следующие основные виды соединений таблиц:
1) Перекрестное соединение
CROSS JOIN — определяются все возможные сочетания пар строк по одной для каждой строки каждой из объединяемых таблиц. Эквивалентно картезианскому соединению. Иногда называет декартовым произведением.
2) Естественное соединение
JOIN — определяются только те строки таблиц А и B, в которых значения столбцов одинаковы. Называют не совсем полноценным эквисоединением. Это автоматическое соединение по нескольким столбцам со всеми одинаковыми именами (join over).
3) Соединение объединением
UNION JOIN — определяются только те строки каждой из таблиц, для которых совпадения не были установлены. Столбцы из другой таблицы заполняются значениями NULL. Отметим, что соединение UNION и оператор UNIUN – это не одно и то же. Соединение противоположно соединению типа INNER.
4) Объединение посредством предиката
JOIN ON — фильтрует строки. Предикат может содержать подзапросы.
5) Объединение посредством имен столбцов
JOIN USING() – определяет соединение только по указанным столбцам, в то время как NATURAL – автоматически по всем одноименным.
Типы соединений
представляет собой один из аргументов: INNER
|{LEFT|RIGHT|FULL}
. INNER
– включает строки, в которых есть столбцы с совпадающими данными объединяемых таблиц. Используется по умолчанию.
. LEFT
– включает все строки таблицы А (левая таблица) и все совпадающие значения из таблицы B. Столбцы несовпадающих строки заполняются NULL-значениями.
. RIGHT
– включает все строки таблицы B (правая таблица) и все совпадающие значения таблицы А. обратный вариант для левого объединения.
. FULL
– включает все строки обеих таблиц. Столбцы совпадающих строк заполнены реальными значениями, а несовпадающих строк – NULL-значениями.
. OUTER (внешний)
– уточняющее слово, означающее, что несовпадающие строки из ведущей таблицы включаются вместе с совпадающими.
Примеры на внешнее объединение:
SELECT * FROM SalesPeople INNER JOIN Customer ON SalesPeople.City=Customer.City
. SELECT * FROM Customer LEFT OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
. SELECT * FROM Customer FULL OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
Картезианские соединения и самообъединения
. Если при включении нескольких таблиц не используются те или иные варианты соединения таблиц, то такие соединения называются картезианскими. Они используются для получения строк из двух различных таблиц. Тогда например, при соединении двух таблиц, каждая из которых содержит по 20 строк, итоговая таблица будет содержать 100 строк – каждая из строк одной таблицы с каждой из строк другой таблицы. SELECT * FROM Customer, Orders.
. Соединения одинаковых таблиц называют самообъединением (self-join).
Раздел WHERE
1. Создание внутренних соединений
Связь между таблицами осуществляют с помощью операторов сравнения, а в список выходных столбцов включают квалификационные имена для одноименных столбцов из исходных таблиц.
Основные виды соединений:
. Эквисоединения
– это соединения таблиц, основанные на равенствах. Связь между таблицами по ключевым столбцам обеспечивает ссылочную целостность. Если при соединении используются первичный и внешний ключ то всегда существует отношение «один-ко-многим» (предок/потомок).
. Тэта-соединения
– это такое соединение, когда в качестве оператора сравнения применяется неравенство (, >=, Примечания по SQL Server
В SQL Server левое, правое и полное соединение можно задать в разделе WHERE с помощью [*]=[*]. Фактически реализуется внешнее соединение, которое у других СУБД реализуется в разделе FROM.
Примеры внутренних соединений
SELECT C.CName, S.SName, S.City FROM SalesPeople S, Customer C WHERE S.City=C.City
SELECT SName, CName FROM SalesPeople, Customer WHERE SName
2. Фильтрация строк выходного множества
Раздел WHERE позволяет также определить, т.е. логическое условие, которое может быть либо истинным, либо ложным. Кроме того, одно или оба сравниваемых значения в предикате могут быть равны NULL, тогда результат сравнения может быть равен UNKNOWN. Оператор SELECT извлекает только те строки из таблиц, для которых имеет значение TRUE, исключая строки, для которых он равен FALSE или UNKNOWN.